diff --git a/content/en/open_source/open_source_api/chat/chat.md b/content/en/open_source/open_source_api/chat/chat.md
new file mode 100644
index 0000000..10ca5b7
--- /dev/null
+++ b/content/en/open_source/open_source_api/chat/chat.md
@@ -0,0 +1,80 @@
+---
+title: Chat
+desc: "An end-to-end RAG loop integrating retrieval, generation, and storage — supporting personalized responses with MemCube and automatic memory crystallization."
+---
+
+:::note
+For a complete reference of API fields and formats, see the [Chat API Documentation](/api_docs/chat/chat).
+:::
+
+**Endpoints**:
+* **Complete Response**: `POST /product/chat/complete`
+* **Streaming Response (SSE)**: `POST /product/chat/stream`
+
+**Description**: The core business orchestration entry point of MemOS. It automatically recalls relevant memories from specified `readable_cube_ids`, generates contextual responses, and optionally writes conversation results back to `writable_cube_ids` for continuous AI self-evolution.
+
+## 1. Core Architecture: ChatHandler Orchestration
+
+1. **Memory Retrieval**: Calls **SearchHandler** based on `readable_cube_ids` to extract relevant facts, preferences, and tool context from isolated Cubes.
+2. **Context-Augmented Generation**: Injects recalled memory fragments into the prompt, then calls the specified LLM (via `model_name_or_path`) to generate a targeted response.
+3. **Automatic Memory Loop**: If `add_message_on_answer=true`, the system calls **AddHandler** to asynchronously store the conversation in the specified Cubes — no manual add call required.
+
+## 2. Key Parameters
+
+### 2.1 Identity & Context
+| Parameter | Type | Required | Description |
+| :--- | :--- | :--- | :--- |
+| **`query`** | `str` | Yes | The user's current question. |
+| **`user_id`** | `str` | Yes | Unique user identifier for auth and data isolation. |
+| `history` | `list` | No | Short-term conversation history for maintaining session coherence. |
+| `session_id` | `str` | No | Session ID. Acts as a "soft signal" to boost recall weight for in-session memories. |
+
+### 2.2 MemCube Read/Write Control
+| Parameter | Type | Default | Description |
+| :--- | :--- | :--- | :--- |
+| **`readable_cube_ids`** | `list` | - | **Read**: Memory Cubes allowed for retrieval (can span personal and shared Cubes). |
+| **`writable_cube_ids`** | `list` | - | **Write**: Target Cubes for auto-generated memories after conversation. |
+| **`add_message_on_answer`** | `bool` | `true` | Whether to enable auto-writeback. Recommended to keep enabled. |
+
+### 2.3 Algorithm & Model Configuration
+| Parameter | Type | Default | Description |
+| :--- | :--- | :--- | :--- |
+| `mode` | `str` | `fast` | Retrieval mode: `fast`, `fine`, `mixture`. |
+| `model_name_or_path` | `str` | - | LLM model name or path. |
+| `system_prompt` | `str` | - | Override the default system prompt. |
+| `temperature` | `float` | - | Sampling temperature for controlling creativity. |
+| `threshold` | `float` | `0.5` | Relevance threshold — memories below this score are filtered out. |
+
+## 3. Response Modes
+
+### 3.1 Complete Response (`/complete`)
+* Returns the full JSON response after the model finishes generation.
+* Best for non-interactive tasks, background processing, or simple applications.
+
+### 3.2 Streaming Response (`/stream`)
+* Uses **Server-Sent Events (SSE)** to push tokens in real time.
+* Best for chatbots and assistants requiring typewriter-style UI feedback.
+
+## 4. Quick Start
+
+```python
+from memos.api.client import MemOSClient
+
+client = MemOSClient(api_key="...", base_url="...")
+
+res = client.chat(
+ user_id="dev_user_01",
+ query="Based on my preferences, suggest an R data cleaning workflow",
+ readable_cube_ids=["private_cube_01", "public_kb_r_lang"],
+ writable_cube_ids=["private_cube_01"],
+ add_message_on_answer=True,
+ mode="fine"
+)
+
+if res:
+ print(f"AI response: {res.data}")
+```
+
+:::note
+**Developer Tip**: For debugging in a Playground environment, use the dedicated stream endpoint `/product/chat/stream/playground`.
+:::
diff --git a/content/en/open_source/open_source_api/core/add_memory.md b/content/en/open_source/open_source_api/core/add_memory.md
new file mode 100644
index 0000000..737cbca
--- /dev/null
+++ b/content/en/open_source/open_source_api/core/add_memory.md
@@ -0,0 +1,68 @@
+---
+title: Add Memory
+desc: "The core production endpoint of MemOS. Leverages MemCube isolation to support personal memory, knowledge bases, and multi-tenant async memory production."
+---
+
+**Endpoint**: `POST /product/add`
+**Description**: The primary entry point for storing unstructured data. It accepts conversation lists, plain text, or metadata and transforms raw data into structured memory fragments. The open-source edition uses **MemCube** for physical memory isolation and dynamic organization.
+
+## 1. Core Mechanism: MemCube Isolation
+
+Understanding MemCube is essential for effective API usage:
+
+* **Isolation Unit**: A MemCube is the atomic unit of memory production. Cubes are fully independent — deduplication and conflict resolution happen only within a single Cube.
+* **Flexible Mapping**:
+ * **Personal Mode**: Pass `user_id` as `writable_cube_ids` to create a private memory space.
+ * **Knowledge Base Mode**: Pass a knowledge base identifier (QID) as `writable_cube_ids` to store content into that knowledge base.
+* **Multi-target Writes**: The API supports writing to multiple Cubes simultaneously for cross-domain synchronization.
+
+## 2. Key Parameters
+
+| Parameter | Type | Required | Default | Description |
+| :--- | :--- | :--- | :--- | :--- |
+| **`user_id`** | `str` | Yes | - | Unique user identifier for permission validation. |
+| **`messages`** | `list/str` | Yes | - | Message list or plain text content to store. |
+| **`writable_cube_ids`** | `list[str]` | Yes | - | **Core**: Target Cube IDs for writing. |
+| **`async_mode`** | `str` | No | `async` | Processing mode: `async` (background queue) or `sync` (blocking). |
+| **`is_feedback`** | `bool` | No | `false` | If `true`, routes to the feedback handler for memory correction. |
+| `session_id` | `str` | No | `default` | Session identifier for conversation context tracking. |
+| `custom_tags` | `list[str]` | No | - | Custom tags for subsequent search filtering. |
+| `info` | `dict` | No | - | Extended metadata. All key-value pairs support filter-based retrieval. |
+| `mode` | `str` | No | - | Effective only when `async_mode='sync'`: `fast` or `fine`. |
+
+## 3. How It Works (Component & Handler)
+
+When a request arrives, the **AddHandler** orchestrates core components:
+
+1. **Multimodal Parsing**: `MemReader` converts `messages` into internal memory objects.
+2. **Feedback Routing**: If `is_feedback=True`, the handler extracts the tail of the conversation as feedback and corrects existing memories instead of generating new facts.
+3. **Async Dispatch**: In `async` mode, `MemScheduler` pushes the task into a queue and the API returns a `task_id` immediately.
+4. **Internal Organization**: The algorithm performs deduplication and fusion within the target Cube to optimize memory quality.
+
+## 4. Quick Start
+
+Use the `MemOSClient` SDK for standardized calls:
+
+```python
+from memos.api.client import MemOSClient
+
+client = MemOSClient(api_key="...", base_url="...")
+
+# Scenario 1: Add memory for a personal user
+client.add_message(
+ user_id="sde_dev_01",
+ writable_cube_ids=["user_01_private"],
+ messages=[{"role": "user", "content": "I'm learning ggplot2 in R."}],
+ async_mode="async",
+ custom_tags=["Programming", "R"]
+)
+
+# Scenario 2: Import content into a knowledge base with feedback
+client.add_message(
+ user_id="admin_01",
+ writable_cube_ids=["kb_finance_2026"],
+ messages="The 2026 financial audit process has been updated. Please see attachment.",
+ is_feedback=True,
+ info={"source": "Internal_Portal"}
+)
+```
diff --git a/content/en/open_source/open_source_api/core/delete_memory.md b/content/en/open_source/open_source_api/core/delete_memory.md
new file mode 100644
index 0000000..e0f04e6
--- /dev/null
+++ b/content/en/open_source/open_source_api/core/delete_memory.md
@@ -0,0 +1,57 @@
+---
+title: Delete Memory
+desc: "Permanently remove memory entries, associated files, or memory sets matching specific filter conditions from a designated MemCube."
+---
+
+**Endpoint**: `POST /product/delete_memory`
+**Description**: Maintains memory store accuracy and compliance. When a user requests information erasure, data becomes stale, or uploaded files need cleanup, this endpoint performs synchronized physical deletion across both vector databases and graph databases.
+
+## 1. Core Mechanism: Cube-level Physical Cleanup
+
+In the open-source edition, deletion follows strict **MemCube** isolation:
+
+* **Scope Restriction**: Deletion is locked to the Cubes specified via `writable_cube_ids` — content in other Cubes is never affected.
+* **Multi-dimensional Deletion**: Supports concurrent cleanup by **memory ID** (precise), **file ID** (cascading), and **filter** (conditional logic).
+* **Atomic Synchronization**: Triggered by **MemoryHandler**, ensuring both vector index entries and graph database entity nodes are removed simultaneously, preventing recall of "phantom" memories.
+
+## 2. Key Parameters
+
+| Parameter | Type | Required | Description |
+| :--- | :--- | :--- | :--- |
+| **`writable_cube_ids`** | `list[str]` | Yes | Target Cube IDs for the deletion operation. |
+| **`memory_ids`** | `list[str]` | No | List of memory UUIDs to delete. |
+| **`file_ids`** | `list[str]` | No | List of original file IDs — all memories derived from these files will also be removed. |
+| **`filter`** | `object` | No | Logical filter. Supports batch deletion by tags, metadata, or timestamps. |
+
+## 3. How It Works (MemoryHandler)
+
+1. **Permission & Routing**: Validates permissions via `user_id` and routes to **MemoryHandler**.
+2. **Locate Storage**: Identifies the underlying **naive_mem_cube** components from `writable_cube_ids`.
+3. **Dispatch Cleanup**:
+ * **By ID**: Directly erases records from the primary database and vector store.
+ * **By Filter**: First retrieves matching memory IDs, then performs bulk physical removal.
+4. **Status Feedback**: Returns success status — affected content immediately disappears from [**Search**](./search_memory.md) results.
+
+## 4. Quick Start
+
+```python
+client = MemOSClient(api_key="...", base_url="...")
+
+# Scenario 1: Delete a single known incorrect memory
+client.delete_memory(
+ writable_cube_ids=["user_01_private"],
+ memory_ids=["2f40be8f-736c-4a5f-aada-9489037769e0"]
+)
+
+# Scenario 2: Batch cleanup all memories with a specific tag
+client.delete_memory(
+ writable_cube_ids=["kb_finance_2026"],
+ filter={"tags": {"contains": "deprecated_policy"}}
+)
+```
+
+## 5. Important Notes
+
+**Irreversibility**: Deletion is physical. Once successful, the memory cannot be recalled via the search API.
+
+**File Cascading**: When deleting by `file_ids`, the system automatically traces and removes all fact memories and summaries derived from those files.
diff --git a/content/en/open_source/open_source_api/core/get_memory.md b/content/en/open_source/open_source_api/core/get_memory.md
new file mode 100644
index 0000000..14a151f
--- /dev/null
+++ b/content/en/open_source/open_source_api/core/get_memory.md
@@ -0,0 +1,80 @@
+---
+title: Get Memories
+desc: "Paginated query or full export of memory collections from a specified Cube, with support for type filtering and subgraph extraction."
+---
+
+**Endpoints**:
+* **Paginated Query**: `POST /product/get_memory`
+* **Full Export**: `POST /product/get_all`
+
+**Description**: List or export memory assets from a specified **MemCube**. These endpoints provide access to raw memory fragments, user preferences, and tool usage records, supporting paginated display and structured exports.
+
+## 1. Core Mechanism: Paginated vs. Full Export
+
+The system provides two access modes via **MemoryHandler**:
+
+* **Business Pagination (`/get_memory`)**:
+ * Designed for frontend UI lists. Supports `page` and `page_size` parameters.
+ * Includes preference memories by default (`include_preference`), enabling lightweight data loading.
+* **Full Export (`/get_all`)**:
+ * Designed for data migration or complex relationship analysis.
+ * Supports `search_query` for extracting related **subgraphs**, or full export by `memory_type` (text/action/parameter).
+
+## 2. Key Parameters
+
+### 2.1 Paginated Query (`/get_memory`)
+
+| Parameter | Type | Required | Description |
+| :--- | :--- | :--- | :--- |
+| **`mem_cube_id`** | `str` | Yes | Target MemCube ID. |
+| **`user_id`** | `str` | No | Unique user identifier. |
+| **`page`** | `int` | No | Page number (starting from 1). Set to `None` for full export. |
+| **`page_size`** | `int` | No | Items per page. |
+| `include_preference` | `bool` | No | Whether to include preference memories. |
+
+### 2.2 Full / Subgraph Export (`/get_all`)
+
+| Parameter | Type | Required | Description |
+| :--- | :--- | :--- | :--- |
+| **`user_id`** | `str` | Yes | User ID. |
+| **`memory_type`** | `str` | Yes | Memory type: `text_mem`, `act_mem`, `para_mem`. |
+| `mem_cube_ids` | `list` | No | Cube IDs to export. |
+| `search_query` | `str` | No | If provided, recalls and returns a related memory subgraph. |
+
+## 3. Quick Start
+
+### 3.1 Frontend Paginated Display
+
+```python
+res = client.get_memory(
+ user_id="sde_dev_01",
+ mem_cube_id="cube_research_01",
+ page=1,
+ page_size=10
+)
+
+for mem in res.data:
+ print(f"[{mem['type']}] {mem['memory_value']}")
+```
+
+### 3.2 Export a Fact Memory Subgraph
+
+```python
+res = client.get_all(
+ user_id="sde_dev_01",
+ memory_type="text_mem",
+ search_query="R language visualization"
+)
+```
+
+## 4. Response Structure
+
+The response `data` contains an array of memory objects. Each memory typically includes:
+
+* `id`: Unique memory identifier — use with [**Get Detail**](./get_memory_by_id.md) or [**Delete**](./delete_memory.md).
+* `memory_value`: Algorithmically processed memory text.
+* `tags`: Associated custom tags.
+
+:::note
+**Developer Tip**: If you already know a memory ID and want to see its full metadata (confidence, usage records, etc.), use the [**Get Memory Detail**](./get_memory_by_id.md) endpoint.
+:::
diff --git a/content/en/open_source/open_source_api/core/get_memory_by_id.md b/content/en/open_source/open_source_api/core/get_memory_by_id.md
new file mode 100644
index 0000000..4af5b42
--- /dev/null
+++ b/content/en/open_source/open_source_api/core/get_memory_by_id.md
@@ -0,0 +1,53 @@
+---
+title: Get Memory Detail
+desc: "Retrieve full metadata for a single memory via its unique ID, including confidence score, background context, and usage history."
+---
+
+**Endpoint**: `GET /product/get_memory/{memory_id}`
+**Description**: Retrieve all underlying details for a single memory entry. Unlike search endpoints that return summary information, this endpoint exposes lifecycle data (vector sync status, AI extraction context) — essential for system management and troubleshooting.
+
+## 1. Why Get Memory Detail?
+
+* **Metadata Inspection**: View the AI's `confidence` score and `background` reasoning when it extracted this memory.
+* **Lifecycle Verification**: Confirm whether `vector_sync` succeeded and check `updated_at` timestamps.
+* **Usage Tracking**: Review `usage` records showing which sessions recalled this memory for generation.
+
+## 2. Key Parameters
+
+This endpoint uses standard RESTful path parameters:
+
+| Parameter | Location | Type | Required | Description |
+| :--- | :--- | :--- | :--- | :--- |
+| **`memory_id`** | Path | `str` | Yes | Memory UUID. Obtain from [**Get Memories**](./get_memory.md) or [**Search**](./search_memory.md) results. |
+
+## 3. How It Works (MemoryHandler)
+
+1. **Direct Query**: **MemoryHandler** bypasses business orchestration, interacting directly with the underlying **naive_mem_cube** component.
+2. **Data Completion**: Pulls the complete `metadata` dictionary from the persistent store — no semantic truncation is applied.
+
+## 4. Response Data
+
+The response `data` object contains these core fields:
+
+| Field | Description |
+| :--- | :--- |
+| **`id`** | Unique memory identifier. |
+| **`memory`** | Memory text content, typically with annotations (e.g., `[user opinion]`). |
+| **`metadata.confidence`** | AI extraction confidence score (0.0–1.0). |
+| **`metadata.type`** | Memory classification: `fact`, `preference`, etc. |
+| **`metadata.background`** | Detailed AI explanation of why this memory was extracted and its context. |
+| **`metadata.usage`** | List of historical timestamps and contexts where this memory was used by the model. |
+| **`metadata.vector_sync`** | Vector database sync status, typically `success`. |
+
+## 5. Quick Start
+
+```python
+mem_id = "2f40be8f-736c-4a5f-aada-9489037769e0"
+
+res = client.get_memory_by_id(memory_id=mem_id)
+
+if res and res.code == 200:
+ metadata = res.data.get('metadata', {})
+ print(f"Background: {metadata.get('background')}")
+ print(f"Sync status: {metadata.get('vector_sync')}")
+```
diff --git a/content/en/open_source/open_source_api/core/search_memory.md b/content/en/open_source/open_source_api/core/search_memory.md
new file mode 100644
index 0000000..a26a208
--- /dev/null
+++ b/content/en/open_source/open_source_api/core/search_memory.md
@@ -0,0 +1,90 @@
+---
+title: Search Memory
+desc: "Leverages MemCube isolation and semantic retrieval with logical filtering to recall the most relevant context from the memory store."
+---
+
+**Endpoint**: `POST /product/search`
+**Description**: The core endpoint for Retrieval-Augmented Generation (RAG) in MemOS. It performs semantic matching across multiple isolated **MemCubes**, automatically recalling relevant facts, user preferences, and tool invocation records.
+
+## 1. Core Mechanism: Readable Cubes
+
+The open-source API uses **`readable_cube_ids`** for flexible retrieval scope control:
+
+* **Cross-Cube Retrieval**: Specify multiple Cube IDs (e.g., `[personal_cube, enterprise_kb_cube]`) — the algorithm recalls the most relevant content from all specified Cubes in parallel.
+* **Soft Signal Weighting**: Passing a `session_id` gives a relevance boost to content within that session. This is a "weight", not a hard filter.
+* **Absolute Isolation**: Cubes not included in `readable_cube_ids` are completely invisible at the algorithm level, ensuring data security in multi-tenant environments.
+
+## 2. Key Parameters
+
+### Retrieval Basics
+| Parameter | Type | Required | Description |
+| :--- | :--- | :--- | :--- |
+| **`query`** | `str` | Yes | The search query for semantic matching. |
+| **`user_id`** | `str` | Yes | Unique identifier of the requesting user. |
+| **`readable_cube_ids`** | `list[str]` | Yes | **Core**: Cube IDs accessible for this search. |
+| **`mode`** | `str` | No | Search strategy: `fast`, `fine`, or `mixture`. |
+
+### Recall Control
+| Parameter | Type | Default | Description |
+| :--- | :--- | :--- | :--- |
+| **`top_k`** | `int` | `10` | Maximum number of text memories to recall. |
+| **`include_preference`** | `bool` | `true` | Whether to recall user preference memories (explicit/implicit). |
+| **`search_tool_memory`** | `bool` | `true` | Whether to recall tool invocation records. |
+| **`filter`** | `dict` | - | Logical filter supporting tag-based and metadata-based precise filtering. |
+| **`dedup`** | `str` | - | Deduplication strategy: `no`, `sim` (semantic), or `None` (exact text dedup). |
+
+## 3. How It Works (SearchHandler Strategies)
+
+When a request arrives, the **SearchHandler** invokes different components based on the specified `mode`:
+
+1. **Query Rewriting**: Uses an LLM to semantically enhance the `query` for improved matching precision.
+2. **Multi-mode Matching**:
+ * **Fast**: Vector-index rapid recall — ideal for latency-sensitive scenarios.
+ * **Fine**: Adds a reranking step for improved relevance.
+ * **Mixture**: Combines semantic search with graph search for deeper relational recall.
+3. **Multi-dimensional Aggregation**: Facts, preferences (`pref_top_k`), and tool memories (`tool_mem_top_k`) are retrieved in parallel and aggregated.
+4. **Post-processing Dedup**: Highly similar memory entries are compressed based on the `dedup` configuration.
+
+## 4. Quick Start
+
+Multi-Cube joint retrieval via SDK:
+
+```python
+from memos.api.client import MemOSClient
+
+client = MemOSClient(api_key="...", base_url="...")
+
+# Retrieve from personal memories and two knowledge bases simultaneously
+res = client.search_memory(
+ user_id="sde_dev_01",
+ query="Based on my previous preferences, suggest R visualization approaches",
+ readable_cube_ids=["user_01_private", "kb_r_lang", "kb_data_viz"],
+ mode="fine",
+ include_preference=True,
+ top_k=5
+)
+
+if res:
+ print(f"Results: {res.data}")
+```
+
+## 5. Advanced: Using Filters
+
+SearchHandler supports complex filters for fine-grained business requirements:
+
+```python
+# Only search memories tagged "Programming" and created after 2026
+search_filter = {
+ "and": [
+ {"tags": {"contains": "Programming"}},
+ {"created_at": {"gt": "2026-01-01"}}
+ ]
+}
+
+res = client.search_memory(
+ query="data cleaning logic",
+ user_id="sde_dev_01",
+ readable_cube_ids=["user_01_private"],
+ filter=search_filter
+)
+```
diff --git a/content/en/open_source/open_source_api/help/error_codes.md b/content/en/open_source/open_source_api/help/error_codes.md
new file mode 100644
index 0000000..12cb897
--- /dev/null
+++ b/content/en/open_source/open_source_api/help/error_codes.md
@@ -0,0 +1,48 @@
+---
+title: Error Codes
+---
+
+| Error Code | Meaning | Recommended Solution |
+| :--- | :--- | :--- |
+| **Parameter Errors** | | |
+| 40000 | Invalid request parameters | Check parameter names, types, and formats |
+| 40001 | Requested data does not exist | Verify the resource ID (e.g., memory_id) |
+| 40002 | Required parameter is empty | Provide missing required fields |
+| 40003 | Parameter is empty | Check that lists or objects are not empty |
+| 40006 | Unsupported type | Check the `type` field value |
+| 40007 | Unsupported file type | Only upload allowed formats (.pdf, .docx, .doc, .txt) |
+| 40008 | Illegal Base64 content | Check the Base64 string for invalid characters |
+| 40009 | Invalid Base64 format | Verify the Base64 encoding format |
+| 40010 | User ID too long | `user_id` must not exceed 100 characters |
+| 40011 | Session ID too long | `conversation_id` must not exceed 100 characters |
+| 40020 | Invalid project ID | Confirm the Project ID format |
+| **Authentication & Permission Errors** | | |
+| 40100 | API Key authentication required | Add a valid API Key to the request header |
+| 40130 | API Key authentication required | Add a valid API Key to the request header |
+| 40132 | API Key is invalid or expired | Check API Key status or regenerate |
+| **Quota & Rate Limiting** | | |
+| 40300 | API call limit exceeded | Request additional quota |
+| 40301 | Request token limit exceeded | Reduce input content or request more quota |
+| 40302 | Response token limit exceeded | Shorten expected output or request more quota |
+| 40303 | Single conversation length exceeded | Reduce single input/output length |
+| 40304 | Total API calls exhausted | Request additional quota |
+| 40305 | Input exceeds single token limit | Reduce input content |
+| 40306 | Memory deletion auth failed | Confirm you have permission to delete this memory |
+| 40307 | Memory to delete does not exist | Check if the memory_id is valid |
+| 40308 | User for memory deletion not found | Check if the user_id is correct |
+| **System & Service Errors** | | |
+| 50000 | Internal system error | Server is busy or encountered an exception — contact support |
+| 50002 | Operation failed | Check operation logic or retry later |
+| 50004 | Memory service temporarily unavailable | Retry memory write/read operations later |
+| 50005 | Search service temporarily unavailable | Retry memory search operations later |
+| **Knowledge Base & Operation Errors** | | |
+| 50103 | File count limit exceeded | Maximum 20 files per upload |
+| 50104 | Single file size exceeded | Ensure each file is under 100MB |
+| 50105 | Total file size exceeded | Ensure total upload size is under 300MB |
+| 50107 | File upload format not supported | Check and change the file format |
+| 50120 | Knowledge base does not exist | Confirm the knowledge base ID |
+| 50123 | Knowledge base not linked to this project | Confirm the knowledge base is authorized for the current project |
+| 50131 | Task does not exist | Check the task_id (common when querying processing status) |
+| 50143 | Failed to add memory | Algorithm service error — retry later |
+| 50144 | Failed to add message | Chat history save failed |
+| 50145 | Failed to save feedback and write memory | Exception during feedback processing |
diff --git a/content/en/open_source/open_source_api/message/feedback.md b/content/en/open_source/open_source_api/message/feedback.md
new file mode 100644
index 0000000..ae46503
--- /dev/null
+++ b/content/en/open_source/open_source_api/message/feedback.md
@@ -0,0 +1,74 @@
+---
+title: Add Feedback
+desc: "Submit user feedback on AI responses to help MemOS correct, optimize, or remove inaccurate memories in real time."
+---
+
+**Endpoint**: `POST /product/feedback`
+**Description**: Processes user feedback on AI responses or stored memories. By analyzing `feedback_content`, the system can automatically locate and modify incorrect facts in a **MemCube**, or adjust memory weights based on positive/negative feedback.
+
+## 1. Core Mechanism: Memory Correction Loop
+
+**FeedbackHandler** provides finer control than the standard add endpoint:
+
+* **Precise Correction**: By providing `retrieved_memory_ids`, the system can directly target specific recalled memories for correction without affecting others.
+* **Contextual Analysis**: Combines `history` (conversation history) to understand the true intent behind feedback (e.g., "You got it wrong — my current company is A, not B").
+* **Corrected Response**: If `corrected_answer=true`, the endpoint returns a new response generated from the corrected facts.
+
+## 2. Key Parameters
+
+| Parameter | Type | Required | Default | Description |
+| :--- | :--- | :--- | :--- | :--- |
+| **`user_id`** | `str` | Yes | - | Unique user identifier. |
+| **`history`** | `list` | Yes | - | Recent conversation history providing feedback context. |
+| **`feedback_content`** | `str` | Yes | - | **Core**: The user's feedback text. |
+| **`writable_cube_ids`** | `list` | No | - | Target Cubes for memory correction. |
+| `retrieved_memory_ids` | `list` | No | - | Optional: Specific memory IDs from the last retrieval that need correction. |
+| `async_mode` | `str` | No | `async` | Processing mode: `async` (background) or `sync` (real-time). |
+| `corrected_answer` | `bool` | No | `false` | Whether to return a corrected response after memory update. |
+| `info` | `dict` | No | - | Additional metadata. |
+
+## 3. How It Works
+
+1. **Conflict Detection**: `FeedbackHandler` compares the `history` with existing memory facts in `writable_cube_ids`.
+2. **Locate & Update**:
+ * If `retrieved_memory_ids` is provided, directly updates the corresponding nodes.
+ * If not provided, uses semantic matching to find the most relevant outdated memories for overwrite or invalidation.
+3. **Weight Adjustment**: For ambiguous feedback, adjusts `confidence` or credibility levels of specific memory entries.
+4. **Async Processing**: In `async` mode, correction logic is executed by `MemScheduler` asynchronously; the API returns a `task_id` immediately.
+
+## 4. Quick Start
+
+```python
+from memos.api.client import MemOSClient
+
+client = MemOSClient(api_key="...", base_url="...")
+
+res = client.add_feedback(
+ user_id="dev_user_01",
+ feedback_content="I'm no longer on a diet. I don't need to control my food intake.",
+ history=[
+ {"role": "assistant", "content": "You're currently dieting. Have you been controlling your calorie intake?"},
+ {"role": "user", "content": "I'm no longer on a diet..."}
+ ],
+ writable_cube_ids=["private_cube_01"],
+ retrieved_memory_ids=["mem_id_old_job_123"],
+ corrected_answer=True
+)
+
+if res and res.code == 200:
+ print(f"Correction progress: {res.message}")
+ if res.data:
+ print(f"Corrected response: {res.data}")
+```
+
+## 5. Use Cases
+
+### 5.1 Correcting AI Inferences
+Provide a "correction" button in the admin panel. When an administrator discovers an incorrect memory entry, call this endpoint for manual correction.
+
+### 5.2 Updating Outdated Preferences
+In a chat UI, when users say things like "that's wrong" or "not like that", automatically trigger this endpoint with `is_feedback=True` for real-time memory purification.
+
+:::note
+If feedback involves a shared knowledge base, ensure the current user has write access to that Cube.
+:::
diff --git a/content/en/open_source/open_source_api/message/get_message.md b/content/en/open_source/open_source_api/message/get_message.md
new file mode 100644
index 0000000..497d0f7
--- /dev/null
+++ b/content/en/open_source/open_source_api/message/get_message.md
@@ -0,0 +1,69 @@
+---
+title: Get Message
+desc: "Retrieve raw user-assistant conversation history from a specified session for building chat UIs or extracting original context."
+---
+
+::warning
+**[Jump to the full API reference here](/api_docs/message/get_message)**
+
+
+
+**This page focuses on the open-source feature overview. For detailed API fields and limits, click the link above.**
+::
+
+**Endpoint**: `POST /product/get/message`
+**Description**: Retrieves the raw conversation records between user and assistant in a specified session. Unlike memory endpoints that return processed summaries, this endpoint returns unprocessed original text — the core endpoint for building chat history features.
+
+## 1. Memory vs. Message
+
+Distinguish between these two data types during development:
+* **Get Memory (`/get_memory`)**: Returns AI-processed **fact and preference summaries** (e.g., "User prefers R for visualization").
+* **Get Message (`/get_message`)**: Returns **raw conversation text** (e.g., "I've been learning R recently, recommend a visualization package").
+
+## 2. Key Parameters
+
+| Parameter | Type | Required | Default | Description |
+| :--- | :--- | :--- | :--- | :--- |
+| `user_id` | `str` | Yes | - | User identifier associated with the messages. |
+| `conversation_id` | `str` | No | `None` | Unique session identifier. |
+| `message_limit_number` | `int` | No | `6` | Maximum messages to return (recommended max: 50). |
+| `conversation_limit_number` | `int` | No | `6` | Maximum conversation histories to return. |
+| `source` | `str` | No | `None` | Message source channel identifier. |
+
+## 3. How It Works
+
+1. **Locate Session**: Searches the underlying store for messages matching the `conversation_id` and user.
+2. **Slice Processing**: Truncates from the latest messages backwards based on `message_limit_number`.
+3. **Security Isolation**: All requests pass through `RequestContextMiddleware` for strict `user_id` ownership validation.
+
+## 4. Quick Start
+
+```python
+from memos.api.client import MemOSClient
+
+client = MemOSClient(
+ api_key="YOUR_LOCAL_API_KEY",
+ base_url="http://localhost:8000/product"
+)
+
+res = client.get_message(
+ user_id="memos_user_123",
+ conversation_id="conv_r_study_001",
+ message_limit_number=10
+)
+
+if res and res.code == 200:
+ for msg in res.data:
+ print(f"[{msg['role']}]: {msg['content']}")
+```
+
+## 5. Use Cases
+
+### 5.1 Chat UI History Loading
+When a user enters a historical session, call this endpoint to restore the conversation. Combine with `message_limit_number` for paginated loading.
+
+### 5.2 External Model Context Injection
+If using a custom LLM pipeline (not the built-in chat endpoint), use this endpoint to fetch raw history and manually prepend it to the model's messages array.
+
+### 5.3 Message Retrospective Analysis
+Periodically export raw conversation records for evaluating AI response quality or analyzing user intent patterns.
diff --git a/content/en/open_source/open_source_api/message/get_suggestion_queries.md b/content/en/open_source/open_source_api/message/get_suggestion_queries.md
new file mode 100644
index 0000000..1e13e60
--- /dev/null
+++ b/content/en/open_source/open_source_api/message/get_suggestion_queries.md
@@ -0,0 +1,64 @@
+---
+title: Get Suggestions
+desc: "Automatically generate 3 follow-up conversation suggestions based on the current dialogue context or recent memories in a Cube."
+---
+
+# Get Suggestion Queries
+
+**Endpoint**: `POST /product/suggestions`
+**Description**: Implements a "suggested questions" feature. The system generates 3 relevant follow-up questions based on the provided conversation context or recent memories in the target **MemCube**, helping users continue the conversation.
+
+## 1. Core Mechanism: Dual-mode Generation
+
+**SuggestionHandler** supports two flexible generation modes:
+
+* **Context-based (Instant Suggestions)**:
+ * **Trigger**: `message` is provided in the request.
+ * **Logic**: Analyzes recent conversation to generate 3 closely related follow-up questions.
+* **Memory-based (Discovery Suggestions)**:
+ * **Trigger**: `message` is not provided.
+ * **Logic**: Retrieves recent memories from the specified `mem_cube_id` and generates inspirational questions about the user's recent activities.
+
+## 2. Key Parameters
+
+| Parameter | Type | Required | Default | Description |
+| :--- | :--- | :--- | :--- | :--- |
+| **`user_id`** | `str` | Yes | - | Unique user identifier. |
+| **`mem_cube_id`** | `str` | Yes | - | **Core**: The memory space for generating suggestions. |
+| **`language`** | `str` | No | `zh` | Language: `zh` (Chinese) or `en` (English). |
+| `message` | `list/str` | No | - | Current conversation context. If provided, generates context-based suggestions. |
+
+## 3. How It Works (SuggestionHandler)
+
+1. **Context Detection**: Checks the `message` field. If present, extracts conversation essence; if empty, queries the underlying `MemCube` for recent dynamics.
+2. **Template Matching**: Automatically switches between Chinese and English prompt templates based on `language`.
+3. **Model Inference**: Calls the LLM to derive 3 questions that are logical and thought-provoking.
+4. **Formatted Output**: Returns suggestions as an array for direct rendering as clickable buttons in the frontend.
+
+## 4. Quick Start
+
+```python
+from memos.api.client import MemOSClient
+
+client = MemOSClient(api_key="...", base_url="...")
+
+res = client.get_suggestions(
+ user_id="dev_user_01",
+ mem_cube_id="private_cube_01",
+ language="en",
+ message=[
+ {"role": "user", "content": "I want to learn R visualization."},
+ {"role": "assistant", "content": "I recommend learning ggplot2 — it's the core visualization tool in R."}
+ ]
+)
+
+if res and res.code == 200:
+ # Example output: ["How do I install ggplot2?", "What are some classic ggplot2 tutorials?", "What other R visualization packages are there?"]
+ print(f"Suggestions: {res.data}")
+```
+
+## 5. Suggested Use Cases
+
+**Conversation Guidance**: After the AI responds, automatically call this endpoint and display suggestion buttons below the reply to encourage deeper exploration.
+
+**Cold Start Activation**: When a user enters a new session without sending a message, use memory-based mode to show topics from past sessions, breaking the silence.
diff --git a/content/en/open_source/open_source_api/scheduler/get_status.md b/content/en/open_source/open_source_api/scheduler/get_status.md
new file mode 100644
index 0000000..4ad7429
--- /dev/null
+++ b/content/en/open_source/open_source_api/scheduler/get_status.md
@@ -0,0 +1,95 @@
+---
+title: Scheduler Status
+desc: "Monitor the full lifecycle of MemOS async tasks, including task progress, queue backlog, and system-wide metrics."
+---
+
+**Endpoints**:
+* **System Overview**: `GET /product/scheduler/allstatus`
+* **Task Progress Query**: `GET /product/scheduler/status`
+* **User Queue Metrics**: `GET /product/scheduler/task_queue_status`
+
+**Description**: These endpoints provide observability for the async memory production pipeline. Track specific task completion status, monitor Redis queue backlogs, and view system-wide scheduling metrics.
+
+## 1. Core Mechanism: MemScheduler System
+
+In the open-source architecture, **MemScheduler** handles all long-running background tasks (LLM memory extraction, vector index building, etc.):
+
+* **State Transitions**: Tasks progress through `waiting` → `in_progress` → `completed` or `failed`.
+* **Queue Monitoring**: Built on Redis Streams for task distribution. Monitor `pending` (delivered but unacknowledged) and `remaining` (queued) counts to assess system pressure.
+* **Multi-dimensional Observability**: View status from three perspectives: single task, per-user queue, and system-wide summary.
+
+## 2. Endpoint Details
+
+### 2.1 Task Progress Query (`/status`)
+
+Tracks the current execution stage of a specific async task.
+
+| Parameter | Type | Required | Description |
+| :--- | :--- | :--- | :--- |
+| **`user_id`** | `str` | Yes | User identifier for the query. |
+| `task_id` | `str` | No | Optional: Query a specific task's status. |
+
+**Status Values**:
+* `waiting`: Task is queued, awaiting a free worker.
+* `in_progress`: Worker is calling the LLM for memory extraction or writing to the database.
+* `completed`: Memory has been persisted and vector index synced.
+* `failed`: Task failed.
+
+### 2.2 User Queue Metrics (`/task_queue_status`)
+
+Monitors a user's task backlog in Redis.
+
+| Parameter | Type | Required | Description |
+| :--- | :--- | :--- | :--- |
+| **`user_id`** | `str` | Yes | User ID to check queue status. |
+
+**Key Metrics**:
+* `pending_tasks_count`: Tasks delivered to workers but not yet acknowledged.
+* `remaining_tasks_count`: Tasks still queued and awaiting assignment.
+* `stream_keys`: Matching Redis Stream key names.
+
+### 2.3 System Overview (`/allstatus`)
+
+Provides a global overview of the scheduler, typically used for admin monitoring.
+
+**Key Response Data**:
+* `scheduler_summary`: Current system load and health status.
+* `all_tasks_summary`: Aggregate statistics for all running and queued tasks.
+
+## 3. How It Works (SchedulerHandler)
+
+1. **Cache Retrieval**: First checks Redis status cache for the `task_id`'s real-time progress.
+2. **Queue Confirmation**: For queue metrics, calls Redis statistics commands (`XLEN`, `XPENDING`) to analyze Stream state.
+3. **Metric Aggregation**: For global status requests, aggregates metrics from all active nodes into a system-level summary.
+
+## 4. Quick Start
+
+```python
+from memos.api.client import MemOSClient
+import time
+
+client = MemOSClient(api_key="...", base_url="...")
+
+# 1. System overview: Check overall MemOS health
+global_res = client.get_all_scheduler_status()
+if global_res:
+ print(f"System overview: {global_res.data['scheduler_summary']}")
+
+# 2. Queue monitoring: Check a user's task backlog
+queue_res = client.get_task_queue_status(user_id="dev_user_01")
+if queue_res:
+ print(f"Pending tasks: {queue_res.data['remaining_tasks_count']}")
+ print(f"Delivered but incomplete: {queue_res.data['pending_tasks_count']}")
+
+# 3. Task progress: Poll until a specific task completes
+task_id = "task_888999"
+while True:
+ res = client.get_task_status(user_id="dev_user_01", task_id=task_id)
+ if res and res.code == 200:
+ current_status = res.data[0]['status']
+ print(f"Task {task_id} status: {current_status}")
+
+ if current_status in ['completed', 'failed', 'cancelled']:
+ break
+ time.sleep(2)
+```
diff --git a/content/en/open_source/open_source_api/start/configuration.md b/content/en/open_source/open_source_api/start/configuration.md
new file mode 100644
index 0000000..b23785b
--- /dev/null
+++ b/content/en/open_source/open_source_api/start/configuration.md
@@ -0,0 +1,7 @@
+---
+title: Project Configuration
+---
+
+For detailed configuration of the MemOS open-source API server — including LLM engines, storage backends, and environment variable setup — please refer to:
+
+👉 [**REST API Server Configuration Guide**](../../../getting_started/rest_api_server.md)
diff --git a/content/en/open_source/open_source_api/start/overview.md b/content/en/open_source/open_source_api/start/overview.md
new file mode 100644
index 0000000..e59d49b
--- /dev/null
+++ b/content/en/open_source/open_source_api/start/overview.md
@@ -0,0 +1,52 @@
+---
+title: Overview
+---
+
+## 1. API Introduction
+
+The MemOS open-source project provides a high-performance REST API service built with **FastAPI**. The system adopts a **Component + Handler** architecture, where all core logic (memory extraction, semantic search, async scheduling) is accessible through standard REST endpoints.
+
+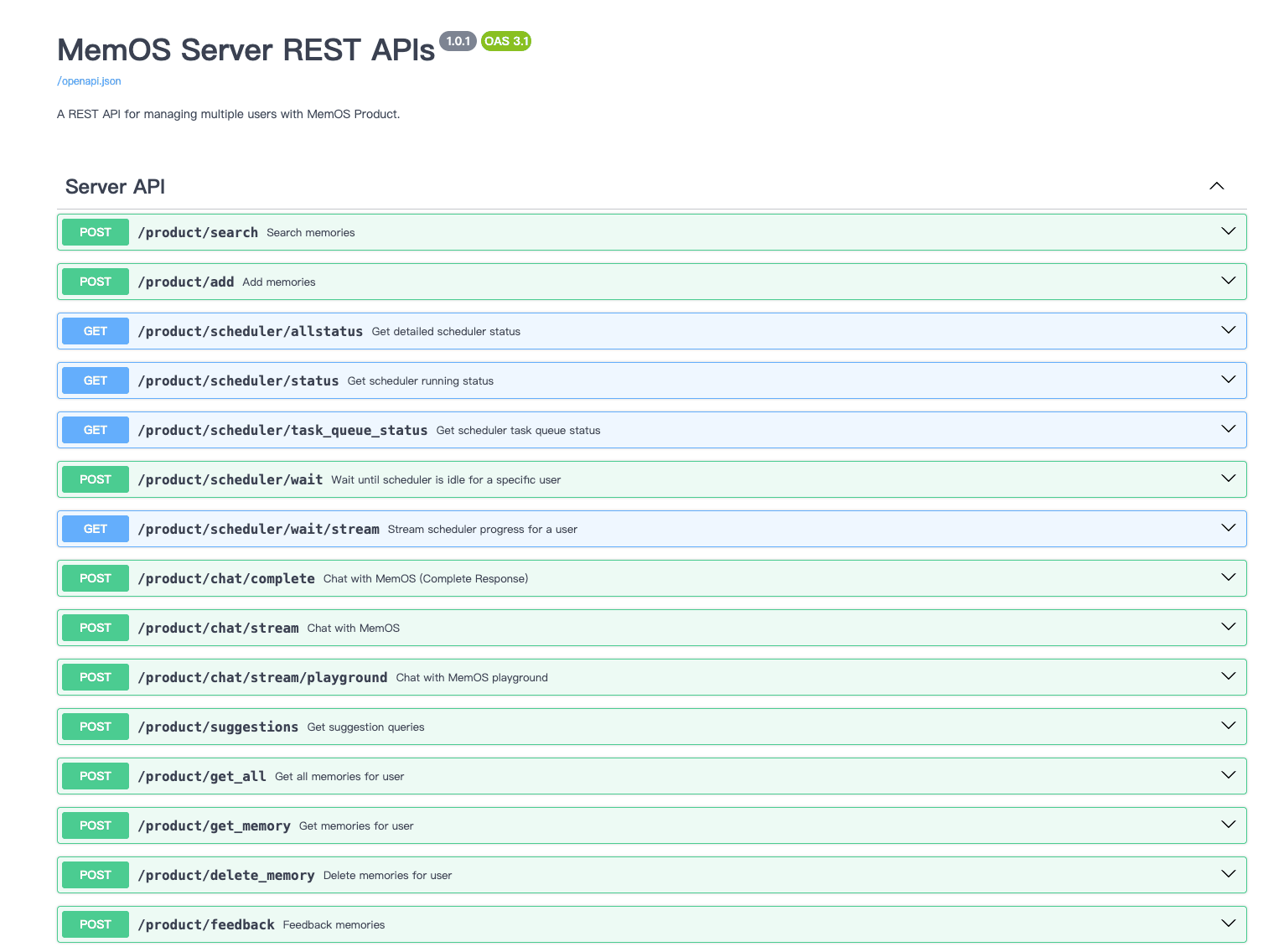
+MemOS REST API Architecture Overview
+
+### Key Features
+
+* **Multi-dimensional Memory Production**: Process conversations, text, or documents through `AddHandler`, automatically transforming them into structured memories.
+* **MemCube Physical Isolation**: Data isolation and independent indexing between users or knowledge bases via Cube IDs.
+* **End-to-end Conversation Loop**: `ChatHandler` orchestrates the full "Retrieval → Generation → Async Storage" pipeline.
+* **Async Task Scheduling**: Built-in `MemScheduler` engine supports load balancing and status tracking for large-scale memory production.
+* **Self-correction Mechanism**: Feedback API allows natural-language corrections to stored memories.
+
+## 2. Getting Started
+
+Integrate memory capabilities into your AI application with two core steps:
+
+* [**Add Memory**](../core/add_memory.md): Use `POST /product/add` to write raw message streams into a specified MemCube.
+* [**Search Memory**](../core/search_memory.md): Use `POST /product/search` to recall relevant context via semantic similarity across multiple Cubes.
+
+## 3. API Categories
+
+MemOS APIs are organized into the following groups:
+
+* **[Core Memory](../core/add_memory.md)**: CRUD operations for memories.
+* **[Chat](../chat/chat.md)**: Memory-augmented streaming or complete chat responses.
+* **[Message](../message/feedback.md)**: User feedback, suggestion queries, and enhanced interactions.
+* **[Scheduler](../scheduler/get_status.md)**: Monitor background memory extraction task progress and queue status.
+* **[Tools](../tools/check_cube.md)**: Cube existence checks and memory-to-user reverse lookups.
+
+## 4. Authentication and Context
+
+### Authentication
+All API requests require an `Authorization` header.
+* **Development**: Define a custom `API_KEY` in your local `.env` or configuration file.
+* **Production**: Extend `RequestContextMiddleware` with OAuth2 or other advanced authentication logic.
+
+### Request Context
+* **user_id**: Must be included in the request body for identity tracking in the Handler layer.
+* **MemCube ID**: The core isolation unit in the open-source edition. Control read/write boundaries precisely by specifying `readable_cube_ids` or `writable_cube_ids`.
+
+## 5. Next Steps
+
+* 👉 [**System Configuration**](./configuration.md): Configure your LLM provider and vector database engine.
+* 👉 [**Add Your First Memory**](../core/add_memory.md): Submit your first batch of conversation messages via SDK or curl.
+* 👉 [**Explore Error Codes**](../help/error_codes.md): Understand API status codes and exception handling.
diff --git a/content/en/open_source/open_source_api/tools/check_cube.md b/content/en/open_source/open_source_api/tools/check_cube.md
new file mode 100644
index 0000000..18c4aa2
--- /dev/null
+++ b/content/en/open_source/open_source_api/tools/check_cube.md
@@ -0,0 +1,43 @@
+---
+title: Check Cube Existence
+desc: "Verify whether a specified MemCube ID has been initialized and is available in the system."
+---
+
+**Endpoint**: `POST /product/exist_mem_cube_id`
+**Description**: Validates whether a `mem_cube_id` exists in the system. A "gatekeeper" endpoint to ensure data consistency — call it before dynamically creating knowledge bases or assigning user spaces to avoid duplicate initialization or invalid operations.
+
+## 1. Core Mechanism: Cube Index Validation
+
+In MemOS, a MemCube's existence determines the validity of all subsequent memory operations:
+
+* **Logical Validation**: **MemoryHandler** queries the underlying storage index to confirm registration.
+* **Cold-start Guarantee**: For on-demand Cube creation scenarios, use this endpoint to decide whether an initial `add` operation is needed to activate the memory space.
+
+## 2. Key Parameters
+
+| Parameter | Type | Required | Description |
+| :--- | :--- | :--- | :--- |
+| **`mem_cube_id`** | `str` | Yes | The MemCube ID to validate. |
+
+## 3. How It Works (MemoryHandler)
+
+1. **Index Query**: **MemoryHandler** calls the underlying **naive_mem_cube** metadata query interface.
+2. **Status Retrieval**: Searches the persistence layer for configuration files or database records matching the ID.
+3. **Boolean Response**: Returns only existence status via `code` or `data` — no memory content is included.
+
+## 4. Quick Start
+
+```python
+from memos.api.client import MemOSClient
+
+client = MemOSClient(api_key="...", base_url="...")
+
+kb_id = "kb_finance_2026"
+res = client.exist_mem_cube_id(mem_cube_id=kb_id)
+
+if res and res.code == 200:
+ if res.data.get('exists'):
+ print(f"MemCube '{kb_id}' is ready.")
+ else:
+ print(f"MemCube '{kb_id}' has not been initialized.")
+```
diff --git a/content/en/open_source/open_source_api/tools/get_user_names.md b/content/en/open_source/open_source_api/tools/get_user_names.md
new file mode 100644
index 0000000..aa5c36d
--- /dev/null
+++ b/content/en/open_source/open_source_api/tools/get_user_names.md
@@ -0,0 +1,44 @@
+---
+title: Get User Names
+desc: "Reverse-lookup the user names associated with specific memory IDs."
+---
+
+**Endpoint**: `POST /product/get_user_names_by_memory_ids`
+**Description**: Provides reverse-tracing capability. When you encounter specific `memory_id` values in system logs or shared storage but cannot identify the originator, use this endpoint to batch-retrieve the associated user names.
+
+## 1. Core Mechanism: Metadata Provenance
+
+In MemOS, every generated memory entry is bound to the original user's metadata. This endpoint traces ownership:
+
+* **Many-to-one Mapping**: Accepts multiple `memory_id` values in a single request and returns the corresponding user list.
+* **Administrative Transparency**: Typically used in admin panels to identify contributors of entries in shared Cubes.
+
+## 2. Key Parameters
+
+| Parameter | Type | Required | Description |
+| :--- | :--- | :--- | :--- |
+| **`memory_ids`** | `list[str]` | Yes | List of memory UUIDs to look up. |
+
+## 3. How It Works (MemoryHandler)
+
+1. **ID Parsing**: **MemoryHandler** receives the ID list and queries the global index.
+2. **Relationship Retrieval**: Extracts associated `user_id` or `user_name` attributes from the persistence layer or graph nodes.
+3. **Data Sanitization**: Returns display names or identifiers based on system configuration.
+
+## 4. Quick Start
+
+```python
+from memos.api.client import MemOSClient
+
+client = MemOSClient(api_key="...", base_url="...")
+
+target_ids = [
+ "2f40be8f-736c-4a5f-aada-9489037769e0",
+ "5e92be1a-826d-4f6e-97ce-98b699eebb98"
+]
+
+res = client.get_user_names_by_memory_ids(memory_ids=target_ids)
+
+if res and res.code == 200:
+ print(f"Memories belong to user(s): {res.data}")
+```
diff --git a/content/en/settings.yml b/content/en/settings.yml
index 270d933..7c5c3fa 100644
--- a/content/en/settings.yml
+++ b/content/en/settings.yml
@@ -66,6 +66,30 @@ nav:
- "(ri:database-2-line) KV Cache Memory": open_source/modules/memories/kv_cache_memory.md
- "(ri:cpu-line) Parametric Memory": open_source/modules/memories/parametric_memory.md
+ - "(ri:file-code-line) Open Source API":
+ - "(ri:rocket-line) Getting Started":
+ - "(ri:eye-line) Overview": open_source/open_source_api/start/overview.md
+ - "(ri:settings-3-line) Configuration": open_source/open_source_api/start/configuration.md
+ - "(ri:edit-box-line) Core Operations":
+ - "(ri:message-3-line) Add Memory": open_source/open_source_api/core/add_memory.md
+ - "(ri:search-2-line) Search Memory": open_source/open_source_api/core/search_memory.md
+ - "(ri:file-list-line) Get Memories": open_source/open_source_api/core/get_memory.md
+ - "(ri:file-search-line) Get Memory Detail": open_source/open_source_api/core/get_memory_by_id.md
+ - "(ri:delete-bin-line) Delete Memory": open_source/open_source_api/core/delete_memory.md
+ - "(ri:chat-smile-2-line) Chat":
+ - "(ri:chat-4-line) Chat": open_source/open_source_api/chat/chat.md
+ - "(ri:chat-1-line) Messages":
+ - "(ri:feedback-line) Add Feedback": open_source/open_source_api/message/feedback.md
+ - "(ri:file-list-line) Get Message": open_source/open_source_api/message/get_message.md
+ - "(ri:question-line) Get Suggestions": open_source/open_source_api/message/get_suggestion_queries.md
+ - "(ri:timer-flash-line) Scheduler":
+ - "(ri:task-line) Task Status": open_source/open_source_api/scheduler/get_status.md
+ - "(ri:tools-line) Tools":
+ - "(ri:checkbox-multiple-blank-line) Check Cube": open_source/open_source_api/tools/check_cube.md
+ - "(ri:user-line) Get User Names": open_source/open_source_api/tools/get_user_names.md
+ - "(ri:customer-service-line) Help":
+ - "(ri:error-warning-line) Error Codes": open_source/open_source_api/help/error_codes.md
+
- "(ri:star-line) Best Practice":
- "(ri:speed-line) Performance Tuning": open_source/best_practice/performance_tuning.md
- "(ri:wifi-line) Network Environment Adaptation": open_source/best_practice/network_workarounds.md